Original
Duplicate
*PDF documents only - images & video excluded.
Entity extraction, redaction detection, and removal tracking — tools the official DOJ site doesn't offer.
We archived files within hours of the initial DOJ release. Since then, files have been quietly removed. Our heatmaps track exactly which documents disappeared and when.
Browse datasets →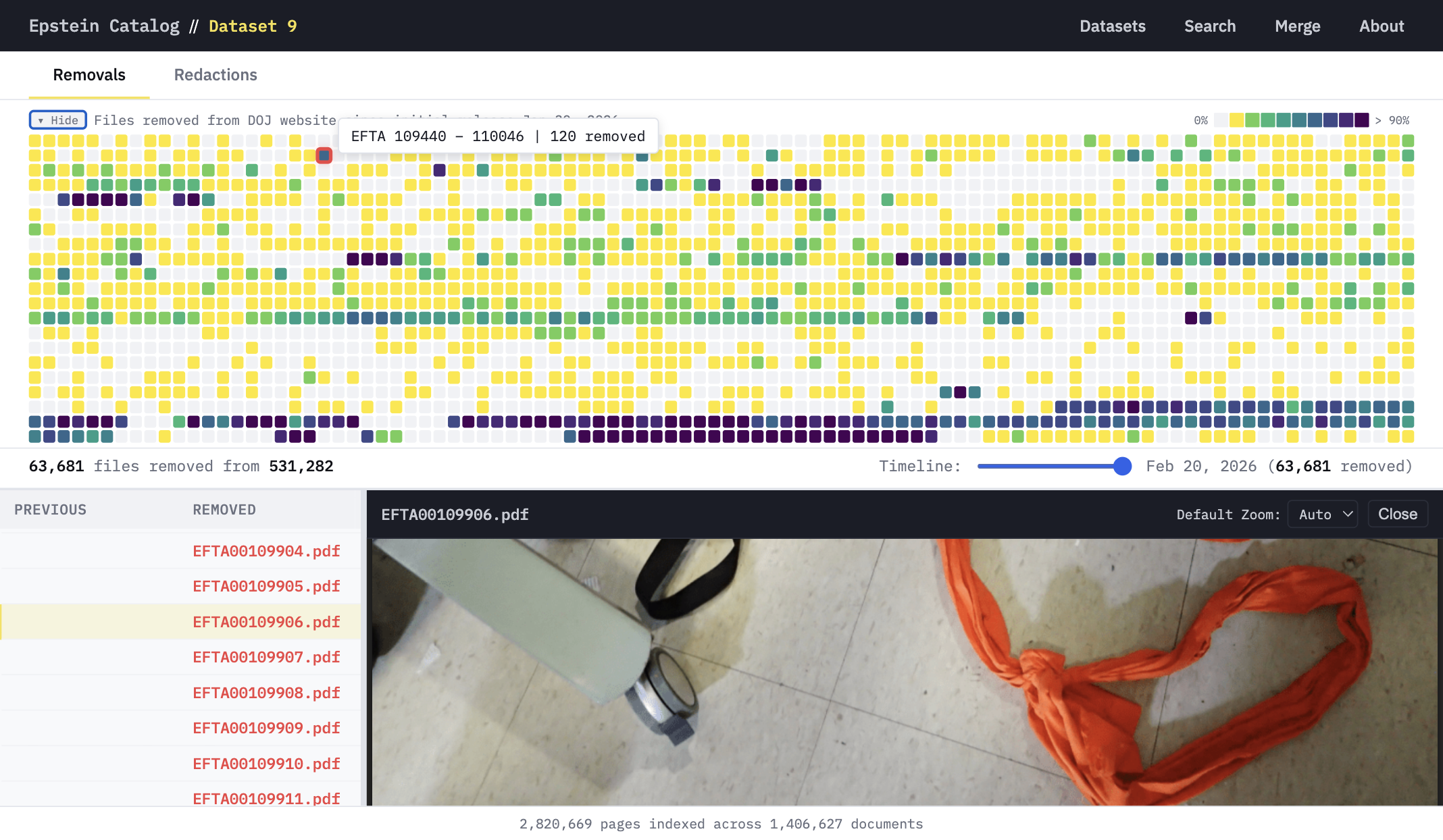
Pixel-level comparison across duplicate files reveals redacted text and subtle alterations invisible to casual readers. Side-by-side comparison reveals every change.
Explore redactions →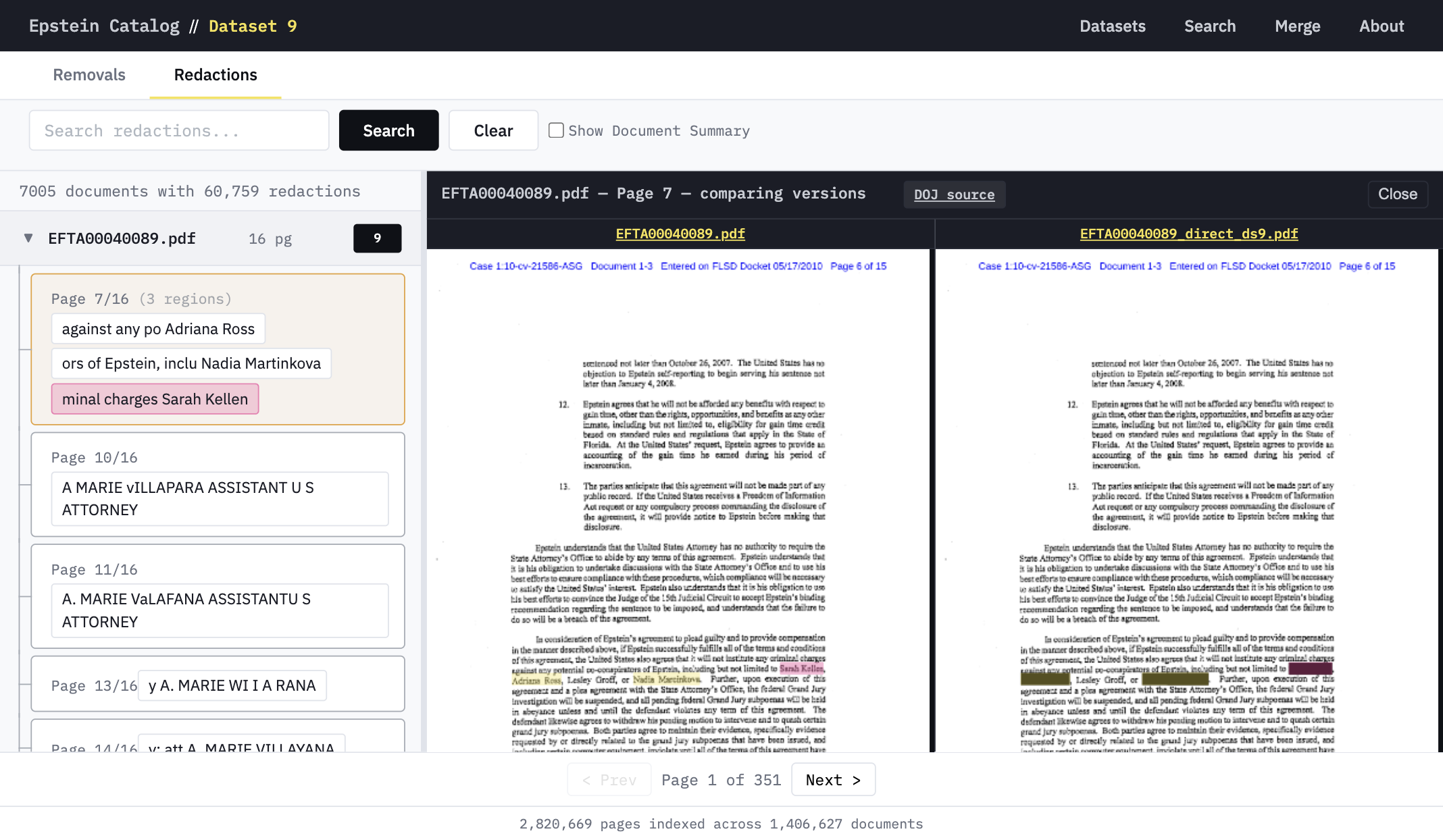
Every page is run through named-entity recognition and regex extraction. Search by person, phone number, email, date, or account number — with exact page references and PDF preview.
Try entity search →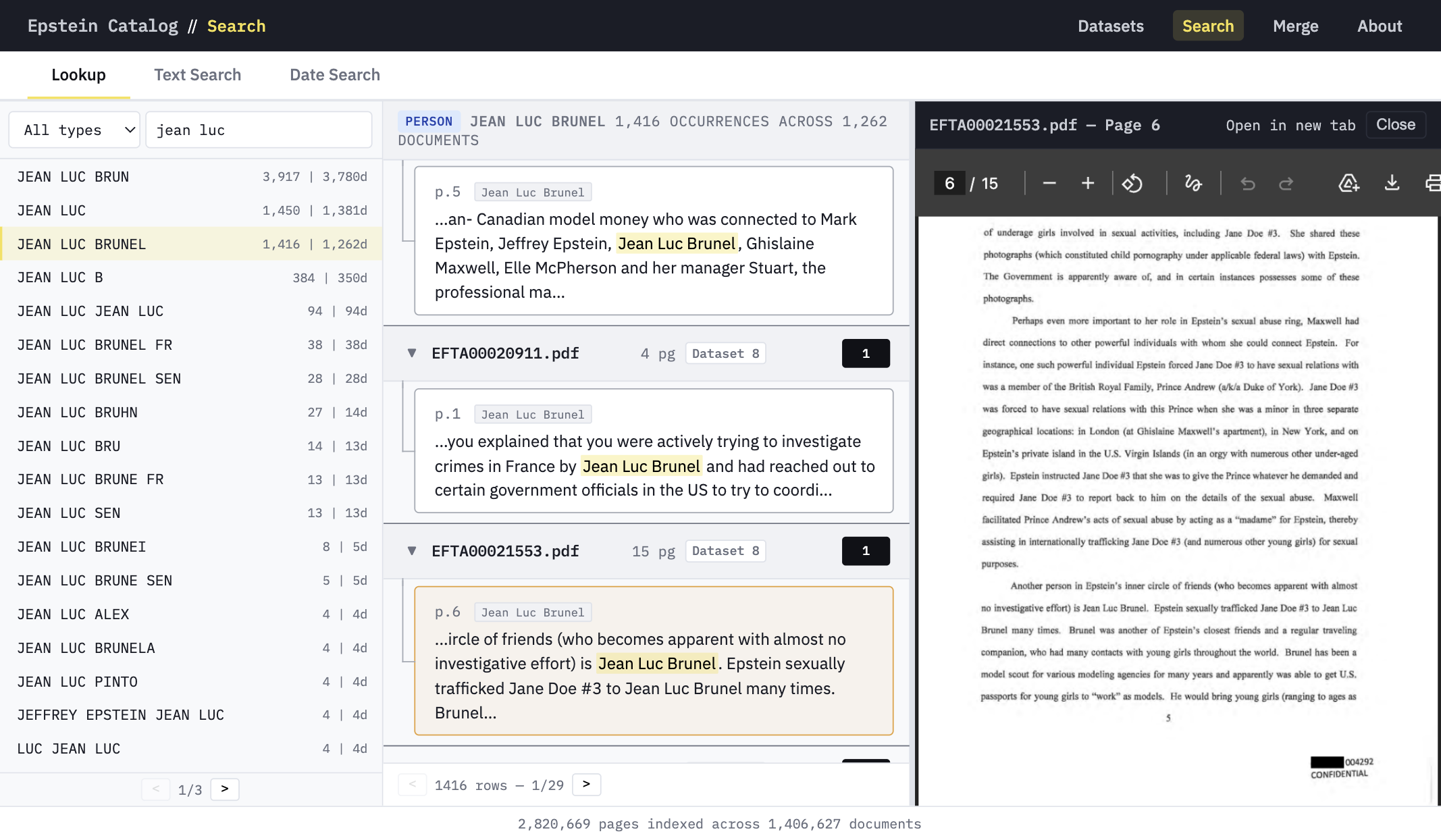
Every page in PDF is classified as text-based or image-based. Text pages are run through OCR, normalized entities extracted, and brief summary added by AI. Image pages are captioned by AI. Documents flagged as likely to contain CSAM are excluded from preview.